I’ve been learning Rust on and off for quite a some time and every time I pick it up again I learn something new. A few days ago when I came back to it again, I was looking for a educational project to do and I decided to implement the Base64 algorithm in Rust. In this post, I will explain how to encode data to base64 in Rust. Decoding from base64 will be covered in a separate blog post, but it’s worth practicing by implementing it yourself. I’ll share the resources I used at the end of this post.
Useful links:
Theory
Now, let’s dive into the theoretical aspects of how base64 works. By the end of this section, we’ll be able to manually encode data to base64 using pen and paper.
The steps to encode a set of characters to base64 are as follows:
- Split the input, typically a sequence of bytes, into groups of three bytes.
- Each group of three bytes corresponds to a total of 24 bits.
- Split the 24 bits into four 6-bit groups.
- Map each 6-bit group to its corresponding base64 character from the character set: A-Z, a-z, 0-9, +, and /.
- If the number of bytes is not divisible by three, add the padding character ‘=’.
Let’s illustrate this process by manually converting the text ‘Rust’ into base64.
- Split the input into groups of three bytes:
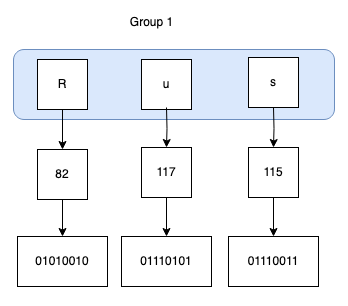
- In the next step, we combine the binary values and split them into four 6-bit groups:
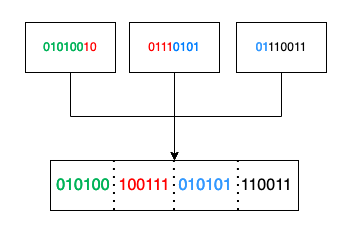
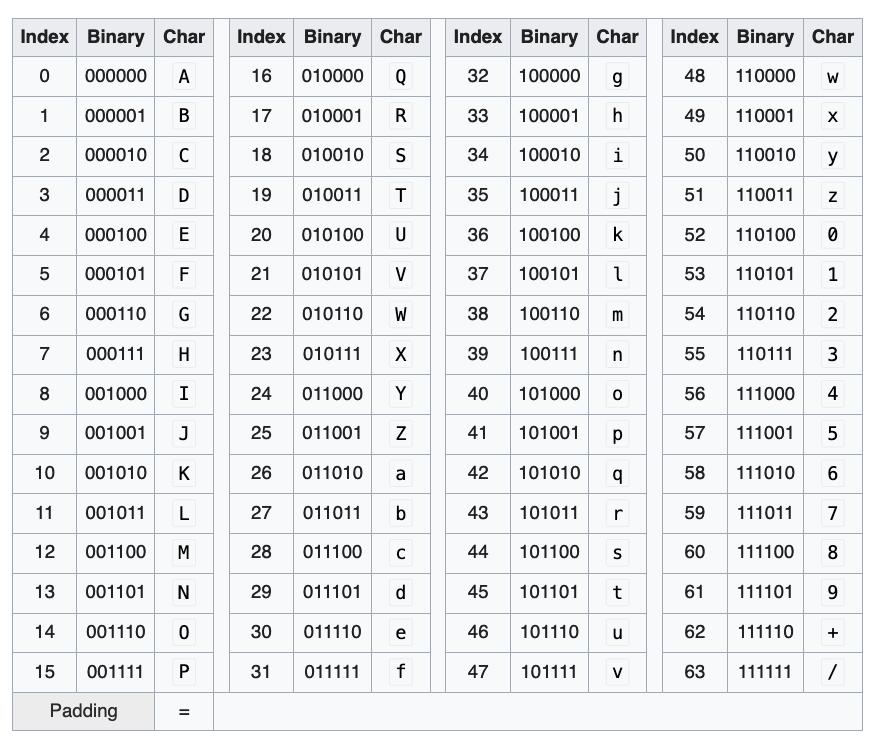
- Now, let’s map each group to its corresponding character using the standard base64 character mapping based on RFC4648 (image from Wikipedia):
- The base64 output for ‘Rus’ is as follows:
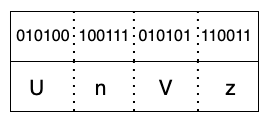
- Next, we continue the same steps for the remaining text. In our case, the only character left is ’t’, which would be encoded as follows:
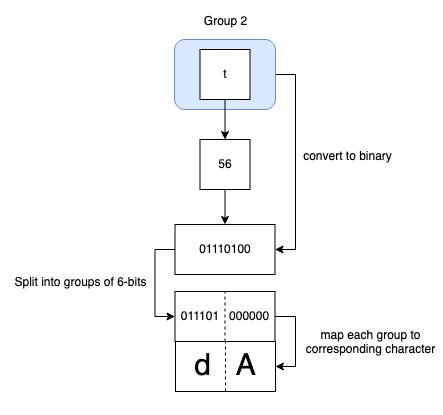
Note that if the last group doesn’t have enough bits, we fill it with 0s until it reaches 6 bits in length.
Adding padding:
So far, our output is UnVzdA, but because it’s not divisible by 3, we need to add the padding character = until it becomes divisible by three.
To calculate how many paddings we need, use the following formula:
r = len(input) % 3
- if
ris equal to 1: we need to add two paddings - if
ris equal to 2: we need to add one padding - if
ris equal to 0: no paddings needed
Since the 4 % 3 = 1 we need to add two paddings at the end and the final output would be UnVzdA==.
Now that we understand the manual conversion process, let’s implement these steps in Rust.
Implementation:
We’ll start by creating a function called encode in a file named base64.rs that takes a series of bytes as input and returns the encoded output as a string:
// file base64.rs
fn encode(input: &[u8]) -> String {
const BASE_CHARS: &[u8] = b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
let mut output = Vec::new();
let input_len = input.len();
for i in (0..input_len).step_by(3) {
let a = input.get(i).unwrap();
let b = input.get(i + 1).unwrap_or(&0);
let c = input.get(i + 2).unwrap_or(&0);
let enc1 = (a >> 2) as usize;
let enc2 = (((a & 0x3) << 4) | (b >> 4)) as usize;
let enc3 = (((b & 0xf) << 2) | (c >> 6)) as usize;
let enc4 = (c & 0x3f) as usize;
output.push(BASE_CHARS[enc1]);
output.push(BASE_CHARS[enc2]);
output.push(BASE_CHARS[enc3]);
output.push(BASE_CHARS[enc4]);
}
let output_len = output.len();
let padding_len = match input_len % 3 {
1 => 2, // Add two padding
2 => 1, // Add one paddings
_ => 0, // No paddings needed
};
for i in 0..padding_len {
output[output_len - 1 - i] = b'=';
}
String::from_utf8(output).unwrap()
}
- In the
forloop we retrieve the first three byte of theinput. Note that the first index is always present but the second and thrid index might be missing. That’s why we usedunwrap_or(&0).
For each group, we perform the necessary bitwise operations to obtain the corresponding base64 characters.
In the line
let enc1 = (a >> 2) as usize;, we use the right shift operator (») to remove the last two bits (MSB) from the variablea. The binary representation of characterRis01010010and by shifting it two times to the right the result is:010100in the next line
let enc2 = (((a & 0x3) << 4) | (b >> 4)) as usize;, first we extract the last two bits ofaby&ing it with0x3(11 in binary), then shift it four times to left and combine the value with first four bits ofb. Theenc2has the value of100111Then we have
let enc3 = (((b & 0xf) << 2) | (c >> 6)) as usize;which extracts the last four bits ofb, shift it two times to right and combine the result with first two bits ofcwhich gives us the values of010101and finally,
let enc4 = (c & 0x3f) as usize;which extracts the remaining bytes fromcby &ing it with0x3f(1111 in binary). Theenc4is equal to110011in binary.At the end of the
forloop we obtain the corresponding base64 characters fromBASE_CHARSand push it to output vector.
We are not done yet, we need to check if the padding is necessary or not:
let output_len = output.len();
let padding_len = match input_len % 3 {
1 => 2, // Add two padding
2 => 1, // Add one paddings
_ => 0, // No paddings needed
};
for i in 0..padding_len {
output[output_len - 1 - i] = b'=';
}
This section of the code determines the number of padding characters required and adds them to the end of the output.
Testing
Let’s write some test to test our algorithm.
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_encode() {
let encoded = encode(b"Rust");
assert_eq!("UnVzdA==", encoded);
}
#[test]
fn encode_has_padding() {
let encoded = encode(b"Rust");
assert!(encoded.ends_with("=="));
}
}
and the result:
running 2 tests
test base64::tests::encode_has_padding ... ok
test base64::tests::test_encode ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Summary
In this post, we achieved two goals simultaneously: understanding the base64 encoding algorithm and gained knowledge about Rust. For me, the step_by function, bitwise operators, and unwrap_or method were particularly new and useful. You can use these resources, or any others you prefer, to learn more about base64 and Rust. It’s a great exercise to try implementing the base64 decoding algorithm.